Developer Area
- Author:
Jacek Dziedzic, University of Southampton
- Author:
James C. Womack, University of Southampton
- Author:
Nicholas Hine, University of Warwick
Advice for Contributors
Pre-pull-request checks
The ONETEP source code is distributed with a number of useful scripts for checking some aspects of the correctness of source code. Before creating a pull request, you should ensure that these tests all pass for the branch you want to merge in your private fork:
Check module dependencies and a few other common issues. Run
make checkdepsor, equivalently,
./utils/check_dependenciesin the root directory of the repository. If any errors are found, fix them.
Check whitespace. Run
./utils/check_whitespacein the root directory of the repository. This script can automatically fix whitespace issues – see the output of
./utils/check_whitespace -hfor details.Check use clauses. Run
./utils/check_use_clauses src/yourmodule_mod.F90in the root directory of the repository, replacing
yourmodulewith the module you worked on. If there was more than one, do this for every module separately. This script checks for unnecessary use clauses and will help point them out. You are only responsible for the use clauses in the code you touched.You must also run the full QC test suite before creating a pull request. Instructions for that can be found here: Compiling, testing and running ONETEP.
- Key points about running the QC test suite before creating a pull request:
Never run the QC tests in the actual repository. Create a copy of your ONETEP installation directory (e.g.
cp -a onetep_jd onetep_jd_qc) and run the tests in the directory of the copy. Much of the stuff in the install is not needed to run the tests (e.g. all ofsrc/), but it’s just less hassle to copy the entire thing than pick out the necessary subdirectories.Why not run the QC tests in the actual repository? Because they produce outputs, which can become messy to clean up back to pristine state, polluting your repository with spurious changes. This becomes more problematic because symbolic links are used in the QC test suite. Trying to update your repository via
git pullorgit fetchmay be tricky when you have unfinished or improperly cleaned up QC tests. Just don’t run them straight in the repository.
You should run the test suite with ONETEP compiled with a recent version of a widely used Fortran compiler, e.g. GNU Fortran, Intel Fortran Classic, Cray Fortran.
The tests should be run in a parallel environment (ONETEP must be compiled with MPI support), ideally also making use of OpenMP threading (set the environment variable
OMP_NUM_THREADSto a value >1, or use the-targument toonetep_launcher).No tests should fail, though warnings are acceptable.
- If tests fail, please investigate this further before creating your pull request:
If you updated your local copy (
git mergeorgit pull) rather than cloning it from scratch (git clone), did you remember tomake cleanallbefore compiling?Check out the master branch from the official repository (ensuring that it is fully updated by fetching from it and merging) and run the failing tests on this.
If the relevant tests do not fail upstream (i.e. for the master branch on the official repository), you should fix the code in your fork before creating your pull request.
If the relevant tests also fail upstream, please check the list of issues in the official repository ( https://github.com/onetep-devel/onetep/issues ): there should be an open issue with relevant information. If such an issue has not been reported, please create a new issue explaining which tests are failing and any details about how the failures occur. If the above link gives you a 404, you are not logged into GitHub.
If the tests are not failing upstream, the problem is likely to be part of the changes you have implemented and you will be the best person to find it and fix it. If you need help, and want to discuss the issue with other developers, you may create an issue in your fork (not in the official repository) and draw their attention to it via email or on the ONETEP development Slack at https://onetep-devel.slack.com/.
If your tests fail in a way in which the official master branch is known to fail, your pull request may be acceptable – you can go ahead creating the pull request, but make sure that the text of the pull request includes a list of the tests that fail and why you think that this is not a problem.
Ensure that the ONETEP version number in your
src/onetep.F90 file is updated appropriately (see
Version numbering for a description
of ONETEP’s version numbering system). If multiple pull requests are open, or
it takes time to merge your pull request, it may be necessary to update the
version number again during the pull request code review. This is to
ensure that the version number increments linearly in the official
repository’s master branch.
Read the next subsection on style conventions to ensure your code adheres to them.
Style conventions
In order to keep the ONETEP codebase relatively consistent and readable, we have adopted the following conventions:
Each line of code should be 80 columns or fewer in length, as this makes comparison of two versions of code side-by-side easier (some older code does not adhere to this, but all new code should).
If a line exceeds 80 columns in length, use continuation characters (
&) to break it into chunks of <=80 characters (remember to include an extra&at the beginning of the following line when breaking in the middle of a string literal). Do not add&in the next line otherwise, it’s unnecessary.Always use spaces for indentation, never tabs.
The blocks in the
doloop,select case(alsoselect type) andifconstructs should be indented by 3 spaces.The contents of subroutines and functions should be indented by 2 spaces. Use further 2 spaces for internals.
Line continuations should be indented by 5 spaces for continued lines.
Ensure there is no trailing whitespace before you commit (you can use the
./utils/check_whitespacescript described in Pre-pull-request checks to check this).In general, adding or removing blank lines should be avoided in core modules, as these changes will appear in the commit history.
New functionality
If you add new procedures or significantly change existing procedures,
you must create or update the documentation in the source code.
Examples of how to document procedures can be found in the template module
template_mod.F90 in the documentation repository. The key components of the
documentation of procedures are:
A human-readable description of the new functionality.
A list of the arguments and a description of their meaning.
The author(s) and a changelog describing significant modifications.
When adding new functionality which does not fit into other modules, it may be necessary to create a new source file containing a new module. Note that procedures and variables should always be encapsulated in modules, not ‘bare’ in a source file.
Before creating a new module, you should consider carefully whether your
new functionality fits within the framework of an existing module, or is
generic enough to be part of a multi-purpose module, such as utils or
services. If a new module is needed to encapsulate some new functionality,
then you should follow the following guidelines:
Give your module a name which indicates the functionality it contains. If unsure, consult a more experienced developer to discuss an appropriate name.
The filename for the module should have the form
<module_name>_mod.F90, where<module_name>is the name you have given the module.By default, variables and procedures in your module should be private (i.e. they should have the
privateattribute).Global module-wide variables (private or public variables declared at the level of the module itself rather than within its routines) constitute “hidden state”, which tends to make the behaviour of a routine undesirably dependent on more than just the arguments it is called with. Sometimes these are unavoidable, and there are instances of them in the code. However, they should be minimised as much as possible. Think carefully before declaring any module-level global variables. More experienced developers may be able to suggest ways to encapsulate data inside arguments to routines such that they do not constitute “hidden state”.
Variables and procedures which do have to be public (accessible outside the module) should be explicitly specified (i.e. they should have the
publica ttribute).In general, public variable and procedure names should be prepended by a standard prefix (typically the module name, or a shortened version of the name).
It is recommended that you make a copy of ./doc/template_mod.F90 and use
this as a starting point for your new module, as this will make following the
above guidelines easier.
Version numbering
There are three parts to the version number, both for development versions and release versions. The first version number is only very rarely incremented by a collective decision of the main authors of the code (ODG). New major versions are released around every 6-12 months and are indicated by incrementing the second number in the full version number (e.g. “2” in “4.2”).
The major version number (second number in full version number) indicates whether the associated source code is a release version or a development version:
Release versions (which are distributed to users) have an even second number.
Development versions (which are under active development) have an odd second number.
Within a series with the same second version number, successive versions (indicated by the third number in the full version number) should be compilable and complete with respect to a given new feature.
For minor changes in development versions (e.g. a bugfix or minor change to
existing code), we no longer increment the fourth number (which is now absent
altogether) to avoid merge conflicts when this is done by multiple people.
The script utils/embed_version_info_in_banner ensures that pertinent
details of the local repository (branch, remote, last commit ID, list of
locally modified files) are included in the ONETEP banner during compilation,
but they do not go into the repository. Major changes (e.g. a new module or
overhaul of existing functionality) should increment the third number.
Bugfixes to a release version (merged into the corresponding release branch on the official repository, e.g. academic_release_v5.0) should increment the last (third) number in the full release version number.
At any given time, there is a development version and a release version differing in their second version number by 1.
4.0.0 <– first release of v4
4.0.1 <– bugfix to v4 in git branch for release
4.1.0 <– first development version of v4 (initially same as 4.0.0)
4.1.0 <– minor development work (changes will be summarised in banner)
4.1.1 <– significant development work
4.2 RC3 <– release candidate 3 for v4.2
4.2.0 <– next release version
4.3.0 <– next development version (initially same as 4.2.0).
5.0.0 <– first release of v5
Preventing accidental pushes to the official repository
GitHub users in the Owner role of the ONETEP repository have write access to the official repository.
Owners may want to take steps to avoid accidentally pushing work to the official repository if they have added this as a remote to their private fork.
This can be achieved by setting the push address for the remote to an unresolvable URL, e.g.:
git remote set-url --push github_official DISABLE
Continuous integration
- Author:
Jacek Dziedzic, University of Southampton
- Author:
Alin-Marin Elena, Science and Technology Facilities Council
- Author:
Chris-Kriton Skylaris, University of Southampton
Since early 2024 ONETEP enjoys modern continuous integration using
GitHub Actions and workflows, which replaces
the earlier effort using buildbot, which has been discontinued.
GitHub Actions and workflows
GitHub Actions is a platform for adding and controlling workflows. There is a tutorial at https://docs.github.com/en/actions/writing-workflows/quickstart if you would like to learn more.
To access GitHub Actions
Go to the repository GitHub page.
If you get a 404 Not Found, make sure you’re logged in to GitHub first, with necessary credentials (Owner).
At the top middle, click on
Actions(play symbol).If you don’t see the
Actionsbutton at all, Actions have been disabled for that repository. You can re-enable them viaSettings(cogwheel), thenActionsin the pane on the left, thenGeneral, checkEnable all actions and reusable workflowsat the top.
A workflow is an automated process – a set of commands to be executed on some triggers (like a push, pull request, schedule, clicking a button in the Actions GUI, etc). Example workflows would be: build ONETEP, deploy documentation, run QC tests.
A workflow run is an instance of a particular workflow, e.g. “build ONETEP #42, ran on 2024-07-07”.
To see a list of ONETEP workflows and workflow runs
Access GitHub Actions (see above).
Workflows will be listed as All workflows in the pane on the left.
Workflow runs will be listed on the right.
Currently, we have the following workflows for the main (code) repository:
Name |
Hosting |
Purpose |
Runs in |
OS |
|---|---|---|---|---|
Build on Docker for ubuntu:noble |
GitHub ( |
Build |
Docker on ubuntu-latest |
ubuntu-noble |
Build in VM on uos-23486 |
Self-hosted ( |
Build |
VM on RHEL 8.9 in Soton |
ubuntu-server 24.04 LTS |
Build on uos-23486 |
Self-hosted ( |
Build |
Physical machine in Soton |
RHEL 8.9 |
Check on uos-23486 |
Self-hosted ( |
Run checks |
Physical machine in Soton |
RHEL 8.9 |
QC-test on uos-23486 |
Self-hosted ( |
Run QC tests |
Physical machine in Soton |
RHEL 8.9 |
Here they are in more detail
GH: Build on Docker for ubuntu:noble – builds ONETEP using
makeand config files in an Ubuntu Noble Docker container running on GitHub’subuntu_latest. Only one platform is built: gfortran+OMP+openmpi+ScaLAPACK. It is defined in.github/workflows/github_hosted_build_on_docker_ubuntu_noble.yml. The Docker image is defined inci/docker_images/ubuntu/noble/Dockerfile. It is run on every push and every pull request.SH: Build in VM (on uos-23486) – builds ONETEP using
makeand config files in an Ubuntu virtual machine set up by Jacek, described in Virtual machine as a self-hosted runner. An extensive list of platforms is built, they are listed in Virtual machine as a self-hosted runner. It is defined in.github/workflows/self_hosted_build_on_soton_runner_vm_jaceks_box.yml. It is run on every push and every pull request.SH: Build on uos-23486 – builds ONETEP using
makeand config files on a RHEL 8.9 physical machine in Soton. Only one platform is built: ifort+OMP+Intel MPI+ScaLAPACK+MKL. It is defined in.github/workflows/self_hosted_build_on_soton_runner_jaceks_box.yml. It is run on every push and every pull request.SH: Check on uos-23486 – runs ONETEP checks (
check_whitespace,check_dependencies_extensive) on a RHEL 8.9 physical machine in Soton. It is defined in.github/workflows/self_hosted_check_on_soton_runner_jaceks_box.yml. It is run on every push and every pull request, and at 4am every day.SH: QC-test on uos-23486 – runs ONETEP QC tests on a RHEL 8.9 physical machine in Soton. Only one platform is tested: ifort+OMP+Intel MPI+ScaLAPACK+MKL. It is defined in
.github/workflows/self_hosted_QC_on_soton_runner_jaceks_box.yml. It is run on every push and every pull request, and at 1am every day.
For the public tutorials repository we only have:
tutorials, set up by Alin, which builds the tutorials with
sphinxand deploys them, via GitHub pages, to tutorials.onetep.org. It is defined in thetutorialsrepository in .github/workflows/tutorials.yml.
For the public documentation repository we only have:
onetep docs, set up by Alin, which builds the documentation with
sphinxand deploys the to GitHub pages. It is defined in thedocumentationrepository in .github/workflows/doc.yml.
There are no workflows (none deemed needed) for the public repository onetep-devel.
Adding and editing workflows
A workflow can be added by adding a YAML file that describes the commands and triggers
to .github/workflows in the repository and committing changes. Alternatively,
it can be added from the GUI by clicking New workflow in the pane on the left.
Workflows can be edited simply by editing these YAML files – either in the repository
and then committing changes, or from the GUI. To do this from the GUI, find the
workflow, click its name in the pane on the left, and then its .yml filename
at the top. Next click the pencil icon on the right. Make necessary changes,
and click the green Commit changes button.
The workflows under .github/workflows are extensively commented, so it should
be easy to create a new one by starting from something that is already there.
Try following the naming convention in the name: field of the .yml
file: hosting-purpose-where.
For hosting, use
GHfor GitHub-hosted orSHfor self-hosted.For purpose, use
Build,CheckorQC-test.Use where, to describe if it’s a Docker container, VM or a physical machine (with location).
Warning
If you add a workflow through your own fork, it will also be featured in your fork, in addition to the main repository. If it is using a self-hosted runner, you probably do not want it to be run from the fork – self-hosted runners are not inherited from the parent repository, and your fork probably does not have any self-hosted runners to run your workflow on. This will result in failures after 24h as the workflows will be unable to run.
To work around this you can either:
Disable
Actionsin your fork viaSettings-Actions-General-Disable actions. This is the sledgehammer approach.Disable every new workflow in your fork via
Actions, clicking on workflow, clickin on...in the top right,Disable workflow. The workflows will show asDisabledin your fork. This is the hammer approach.Add
if: github.repository == 'onetep-devel/onetepbeforeruns-on:in your workflow YAML file. This means you will have a copy of the workflow in your fork, but it will be skipped. This is probably the rational approach, and we do this for all ONETEP workflows.
When forking the main repository, workflows are not transferred to the fork, so this only matters when adding new workflows via a fork.
To quickly test a workflow
Add
workflow_dispatch:to its list of triggers (like ONETEP does for all workflows). This adds aRun workflowbutton above the list of workflow runs. This button lets you run a workflow manually. Very useful!
GitHub-hosted runners
Runners are machines that execute jobs in a Github Actions workflow.
They can be GitHub-hosted (described here), or self-hosted (described under Self-hosted runners).
GitHub-hosted runners are virtual machines with tools preinstalled, set up in
the GitHub cloud. To use a GitHub-hosted runner, specify “runs-on” in the
workflow YAML file, e.g. runs-on: ubuntu-latest.
For a quick description and list of available GitHub-hosted runners see About GitHub-hosted runners. This webpage also lists software installed on each runner, and the VM’s hardware specs. The specs are different for public repositories (better specs, unlimited minutes) and private repositories (worse specs, pool of free minutes, then charged via billing).
For instance ubuntu-latest currently uses ubuntu-22.04 LTS, with the following specs:
4 CPUs, 16 GB of RAM and 14 GB of SSD (for public repositories),
2 CPUs, 7 GB of RAM, 14 GB of SSD (for private repositories).
On Linux GitHub-hosted runners passwordless sudo is in effect.
- We use GitHub-hosted runners for the following lightweight workflows:
GH: Build on Docker for ubuntu:noble,
tutorials,
onetep docs.
For more involved workflows, we use Self-hosted runners.
Self-hosted runners
Self-hosted runners
Self-hosted runners are machines under our control that execute jobs defined by Github Actions. They can be physical machines, virtual machines (VMs), containers, or can live in the cloud.
A self-hosted runner machine connects to GitHub using the GitHub Actions self-hosted runner application. The GitHub Actions runner application is open source. Instructions for downloading the application are shown when a new self-hosted runner is added from the GitHub web GUI. The application auto-updates.
Warning
A self-hosted runner is automatically removed from GitHub if it has not connected to GitHub Actions for more than 14 days.
Self-hosted runners should only be used for private repositories, otherwise they could be used to run untrusted code. The ONETEP repository is private.
Requirements for self-hosted runners can be found at Requirements for self-hosted runner machines. In short:
Must be able to run the self-hosted runner application. Example supported linuces:
RHEL 8 or newer
Debian 10 or newer
Ubuntu 20.04 or newer
Needs to be able to communicate with Github Actions.
The self-hosted runner connects to GitHub to receive job assignments and to download new versions of the runner application. They talk over HTTPS port 443.
There is no need to allow inbound connections from GitHub to the self-hosted runner, only a connection to github.com is needed.
Sufficient hardware to run our jobs.
If Docker container actions needed, Docker must be installed.
To add a self-hosted runner, you must be the repository owner. Follow Instructions for adding a self-hosted runner – they describe the steps for obtaining, installing, configuring and running the GitHub Actions application that must be present on the self-hosted runner. These are also mentioned in steps C and D in Preparing an Ubuntu VM for a self-hosted github runner from scratch. Take a look at that too.
In the YAML file, make sure you have runs-on: [self-hosted, your-runner-label],
where you need to replace your-runner-label with the label you gave it
when configuring the GitHub Actions application.
To see a list of our self-hosted runners
Go to the repository GitHub page. If you get a 404 Not Found, make sure you’re logged in to GitHub first, with necessary credentials (Owner).
At the top right, click on
Settings(cogwheel).In the left pane, under
Actions, chooseRunners.
- A self-hosted runner can execute workflows:
directly (“on the bare metal”),
using a VM (Virtual machine as a self-hosted runner),
using Docker containers (Docker containers as runners).
Virtual machine as a self-hosted runner
Using a virtual machine as a self-hosted runner has the advantage of easy portability. Once the VM is set up, it can be transferred to any physical machine that has VirtualBox installed. ONETEP’s first VM is a Ubuntu server 24.04 LTS install, with the following compilers:
Intel Fortran Classic 2021.13.0 20240602 (possibly the last version in this line of compilers),
Intel Fortran (ifx) 2024.2.0 20240602,
GNU Fortran v13.2.0,
nvfortran 24.7-0,
and the following MPI versions:
openmpi 4.1.6 (installed system-wide),
openmpi 4.1.7a1 (bundled with nvfortran),
mpich 4.2.0 (installed system-wide),
Intel MPI 2021.13 Build 20240515 (bundled with Intel oneAPI).
ScaLAPACK, OpenMP, CUDA, FFTW3 and MKL are also installed.
There are config files for the following combinations to be found under ./config/conf.runner_vbox.*:
gfortran.no_omp.no_mpi,gfortran.omp.mpich.scalapack,gfortran.omp.openmpi.scalapack,ifort.omp.intelmpi.scalapack.mkl,ifx.omp.intelmpi.scalapack.mkl,nvfortran.omp.openmpi.acc,nvfortran.omp.openmpi.cuda.
The Github Action SH: Build in VM (on uos-23486) currently only builds these seven options. This happens on every push and every pull request.
An 8.7GB compressed file of the VM is stored on the ODG google drive, for lack of better hosting options. If you have a spare machine with VirtualBox, I encourage you to simply download it and add it to your VirtualBox. Once run, it will automatically listen to GitHub and execute Actions.
Here are instructions for setting this up:
Install VirtualBox on your machine.
Ask Jacek for a link to download the VM. We are not publicly sharing the link, because the GitHub token could be (with difficulty) salvaged from the VM disk file. Anyone with the VM would technically be able to clone the ONETEP repository.
The VM does not have the GitHub Actions application installed. This is because the installation and configuration needs to be done separately on every instance of the runner. At least one instance is already running somewhere in Southampton, you do not want to confuse GitHub with another one that would be using the same token. So,
Log into the VM, use the username
onetepand the passwordonetep.Complete only steps C and D in Preparing an Ubuntu VM for a self-hosted github runner from scratch. This involves setting up a new runner in GitHub Actions, and building a new
$HOME/actions-runner. It is a simple process.
That’s it, you’re done. Every time you will boot up the VM, it will listen for connections from GitHub Actions.
Starting and stopping the VM remotely
The box on which you will be running the VM will occasionally have to be shut down, or rebooted. If you’re not physically there to start the VM anew from the GUI, and don’t have the patience of a saint to start it via ssh + X11, here’s how to start and stop the VM remotely.
First, find out the name of the VM:
VBoxManage list vms
On my machine this lists just one VM:
"self-hosted-runner-ubuntu" {91d15f0a-000d-44fc-91c6-68452ca6bd2b}
The name of the VM is the bit in double quotes. To start the VM (assuming it has the same name as here):
VBoxManage startvm "self-hosted-runner-ubuntu" --type headless
disown -ah
This starts the VM in the background. If you run top, you will notice a
process with the name VBoxHeadless running. The additional disown -ah
is to make sure that the newly started process doesn’t die when you log off.
An alternative is to use nohup or screen to ensure the same thing.
Warning
My tests, and internet lore, indicate that it is absolutely crucial that you
log in to the physical machine without X11 forwarding. Otherwise, the shell
will pause at logout when you exit, and pressing ctrl-C to finish
the logging out will terminate your VBoxHeadless process, regardless of
the use of disown -ah, nohup or screen. IOW, the machine dies on
logout when you use X11. No idea why that is, as we are not using X11 in
headless mode.
If you need to shut down the VM from remote, issue:
VBoxManage controlvm "self-hosted-runner-ubuntu" poweroff
This is equivalent to pulling the cable on the VM. If you’d like to be more graceful, you can do:
VBoxManage controlvm "self-hosted-runner-ubuntu" acpipowerbutton
This will emulate pressing the ACPI power button, which, with a bit of luck, should lead to a graceful shutdown. Note that:
VBoxManage controlvm "self-hosted-runner-ubuntu" shutdown
does not work without Guest Additions installed, and these would normally be absent on the VM.
Finally, to list running VMs, you can issue:
VBoxManage list runningvms
Preparing an Ubuntu VM for a self-hosted github runner from scratch
It would be best not to reinvent the wheel and use the one Jacek prepared in 2024.08. It uses ubuntu-server 24.04 LTS.
In case anyone needs to create a new one at some point in the future, here goes:
Create a new VM in VirtualBox.
Give it 4 or 8 CPU cores and plenty of RAM. I chose 12000 MB.
Under
System/Processormake sure to selectEnable PAE/NXandEnable Nested VT-x/AMD-V.Do not touch the
Execution Cap.Under
Acceleration, chooseDefaultfor theParavirtualization Interface, and selectEnable Nested Paging.Under
Storage, add a SATA Controller and to it a newly created VDI with a 40-50 GB of space, usedynamically allocated storage.Under
Storage, to the same SATA Controller add an optical drive and attach the bootable ubuntu ISO to it. I used Xubuntu-minimal 24.04 LTS, a server version would probably be a better idea, because we do not want X11 or Wayland on this VM.Under
Network, make sureEnable Network Adapteris selected. I choseIntel PRO/1000 MT Desktopfor the adapter. It’s better than the default at reattaching correctly after a network connectivity interruption on the host.The remaining settings are irrelevant.
Boot the VM from the optical drive, install ubuntu to the newly created VDI. Create a single user, e.g.
onetepwith a password of your choice, e.g.onetep. Anyone with access to the VM will be able to fetch the repository, but that’s about it, security-wise. The VM will not have SSH access. Turn off the VM.Detach the ISO from the optical drive. Boot into the freshly installed system. Log in as the user you created.
Do not install VirtualBox guest additions, as they do not respond well to changes in the version number of the Oracle VirtualBox installation itself, and you want the VM to be portable between different versions of VirtualBox. That means, unfortunately, there will be no bidirectional clipboard between the VM and the host OS. If there is a lot of typing, create a shared folder to paste things into on the host and copy them over from there on the guest.
sudo apt installthe following packages:curl docker.io expect gfortran git make mc libfftw3-bin libfftw3-dev libfftw3-doc libmpich-dev libopenmpi-dev libopenblas-dev libscalapack-mpich-dev libscalapack-openmpi-dev openmpi-bin openmpi-common openmpi-doc plocate
Download Intel oneAPI Base Toolkit, I used 2024.2.0. It is a prerequisite for Intel HPC Toolkit, which you will need too, because it includes the Fortran compiler.
Choose the Linux version.
Don’t give out your email or name, don’t agree to marketing communication. Instead, click continue as guest.
Once you have the installer, run it using
sudo. Go throughAccept and customizeto be able to select packages. Select ONLY MKL, or else you will install a lot of unnecessary stuff. If prompted, skip Eclipse IDE configuration.Download Intel HPC Toolkit Online Installer. This includes the Fortran compilers and Intel MPI.
Choose the Linux version.
Don’t give out your email or name, don’t agree to marketing communication. Instead, click continue as guest.
Once you have the installer, run it using
sudo. Go throughAccept and customizeto be able to select packages. If prompted, skip Eclipse IDE configuration.Deselect everyting with “C++” or “DPC++” in the name, or else you will install a lot of unnecessary stuff.
You will now have a working Intel oneAPI install in
/opt/intel.
Get
nvhpcviaaptby following the instructions from NVIDIA.At the time of writing of this document, these were:
curl https://developer.download.nvidia.com/hpc-sdk/ubuntu/DEB-GPG-KEY-NVIDIA-HPC-SDK | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-hpcsdk-archive-keyring.gpg echo 'deb [signed-by=/usr/share/keyrings/nvidia-hpcsdk-archive-keyring.gpg] https://developer.download.nvidia.com/hpc-sdk/ubuntu/amd64 /' | sudo tee /etc/apt/sources.list.d/nvhpc.list sudo apt-get update -y sudo apt-get install -y nvhpc-24-7
Once this is done, you’ll have
nvhpcin/opt/nvidia.
Perform Docker post-installation set-up by issuing these two commands:
sudo groupadd docker sudo usermod -aG docker $USER
This is necessary to be able to run
dockerwithoutsudo. This is how GitHub Actions run docker, so will be necessary if you plan to usedockeron the VM. You can skip this step if you plan to run directly on the VM.Install the GitHub runner app, as described at https://docs.github.com/en/actions/hosting-your-own-runners/managing-self-hosted-runners/adding-self-hosted-runners which will likely get you to https://github.com/onetep-devel/onetep/settings/actions/runners/new. If you get a 404 instead, you are not logged into your (correct) GitHub account.
This needs to be done by a repository owner because the instructions that will be generated will contain a token that lets the runner clone the repository without you having to share your PAT credentials.
At the time of writing of this document, the instructions looked like this:
# Create a folder mkdir actions-runner && cd actions-runner # Download the latest runner package curl -o actions-runner-linux-x64-2.317.0.tar.gz -L https://github.com/actions/runner/releases/download/v2.317.0/actions-runner-linux-x64-2.317.0.tar.gz # Extract the installer tar xzf ./actions-runner-linux-x64-2.317.0.tar.gz # Create the runner and start the configuration experience ./config.sh --url https://github.com/onetep-devel/onetep --token [___REDACTED___]
… but they can change (e.g. the name and address of the the
.tar.gzfile gets updated).During the configuration stage you will be asked a few questions. Here are the recommended answers:
For name of group, press
Enterto use the default.For name of runner, pick something clear, e.g. I chose onetep-vm-on-jaceks-box.
For label, also pick something clear, e.g. I chose soton-runner-vm-jaceks-box. The label is referenced later in the
.ymlfile in theruns-on:section – you want your workflow to run not on all self-hosted runners, but on this specific runner.For name of work folder, press
Enterto use the defailt.
Set up the github application to run automatically as a service so that you won’t even have to log in to the VM (just boot it up) to have a runner. This can be done with:
cd $HOME/actions-runner sudo ./svc.sh install reboot
For environments where you do not have
sudo(e.g. for running on bare metal rather than a VM), you will instead have to:cd $HOME/actions-runner ./run.sh >stdout 2>stderr & disown -ah
every time you boot the machine.
Warning
Make sure you do not sudo ./run.sh. This will start the runner as root,
which is insecure and mpirun may refuse to run as root.
If this happens, to recover you will have to nuke
the _work directory because it will now be owned by root, preventing
future, correctly-started instances from writing to it or removing it.
If you used a non-server ISO, best to get rid of booting to X11. You can skip this step if you picked a server ISO in step 1. As root or a sudoer edit
/etc/default/grubto include:GRUB_CMDLINE_LINUX_DEFAULT="text" GRUB_TERMINAL=console
This may require adjusting lines that are already there, uncommenting lines that are already there, or adding new lines.
Subsequently, issue:
sudo update-grub sudo systemctl enable multi-user.target --force sudo systemctl set-default multi-user.target
This produced some warnings for me and didn’t work the first time around. However, after I did:
sudo reboot sudo systemctl set-default multi-user.target
it worked. Maybe it’s just a matter of not doing
--force, or maybe a reboot was required.
Set up the github application to run automatically as a service so that you won’t even have to log in to the VM (just boot it up) to have a runner. This can be done with:
cd $HOME/actions-runner sudo ./svc.sh install reboot
[Optional] To make the
.vdifile that represents the HDD storage of the VM compressible better, we can take an additional step. When files are deleted in the VM, the space they used to occupy is not zeroed. That makes the.vdifile compress poorly. We will now zero all unused space. First, in the VM:sudo dd if=/dev/zero of=/var/tmp/bigemptyfile bs=4096k sudo rm /var/tmp/bigemptyfile
Then shut down the VM. Subsequently on the host:
VBoxManage.exe modifymedium --compact path_to_vdi
This compacts the image, making use of the zeroed blocks.
You might need to add a path to your VirtualBox installation before
VBoxManage.exe. Of course, replacepath_to_vdiwith the path and name of the.vdifile you’re compacting.Your
.vdifile will now compress better.Write down the username and the password in a secure place.
Docker containers as runners
A Docker container is a way to run in an isolated environment to ensure reproducible builds. It is more light-weight than a virtual machine (VM). One crucial difference between a Docker container and a VM is that the Docker container does not retain state. Every time it is instantiated, it starts fresh. Thus, when using Docker containers, we do not have to worry about any potential cleanup.
A Docker image is a template for an image. You can think of a Docker container as a running instance of a Docker image.
For more about Docker and Docker containers, see docker for beginners.
In the context of GitHub Action workflows, Docker containers can be used both for running on GitHub-hosted runners and of self-hosted runners. GitHub-hosted runners already have Docker installed. For using Docker on self-hosted runners, whether directly or in a VM, Docker must be installed and a small post-install step needs to be performed.
Installing Docker
The method for installing Docker will differ depending on the OS. On Ubuntu it should be as simple as:
sudo apt install docker.io docker-buildx
On Red Hat:
sudo yum install docker
installs podman, which is an alternative to Docker, with a docker emulation
mode.
Once you install Docker, it typically requires sudo to run. This is not
only cumbersome, but also won’t work with GitHub Actions, which do not apply
sudo to Docker commands. To help with this, on Ubuntu, issue the following
commands:
sudo groupadd docker
sudo usermod -aG docker $USER
… and reboot. This only needs to be done once, after Docker is installed.
Podman, it seems, requires a more complicated post-install step, described at https://github.com/containers/podman/blob/main/docs/tutorials/rootless_tutorial.md. For me, the following steps worked:
sudo yum install slirp4netns
usermod --add-subuids 100000-165535 --add-subgids 100000-165535 $USER
… and rebooting.
To test your Docker installation, you can issue:
docker images
This should finish without any error messages and offer you an empty list of images, because you haven’t created any.
To further test your Docker installation (to see if it can access the Web and write local files), you can issue:
docker pull hello-world
This too should finish without any error messages.
A Dockerfile is a set of instructions, or a recipe, for building a Docker
image. We have several of these, they reside in ./ci/docker_images.
They typically start from a ready-made image provided by the docker.io
repository, and then add any prerequisites needed for compiling or testing
ONETEP.
To pull an image from the docker.io repository, issue something like:
docker pull ubuntu:noble
This will get the latest image of Ubuntu Noble. ubuntu is the repository,
while noble is the tag. If you do not have that image on your machine,
it will be pulled in its entirety (~80 MB, it’s very basic). If you pulled
it before, only the differences will have to be pulled. In any case, you will
wind up with a full image.
You cannot (easily) observe the content of the images directly, but you can issue:
docker images
to view a list of the images on your system.
To work with images that are not just copies of stock images that you pulled,
but install whatever you might need on top, prepare a Dockerfile. You can
use the one in ./ci/docker_images/ubuntu/noble as an example. The following
command builds an image using Dockerfile in the current directory as a recipe:
docker build -t onetep:noble .
The resultant image will be called onetep:noble. The Dockerfile is taken
from the current directory (hence the .).
Issuing:
docker images
again will reveal a new image on our machine, called onetep:noble.
To boot up a container from this image, simply issue:
docker run -it onetep:noble
This will log you in as root into the container. Use exit to leave.
To list running containers (as opposed to static images), use:
docker ps
Warning
Light-weight ubuntu Docker images do not have CA certificates set up.
This will bite you when a workflow using the Docker container image
tries to git pull the repository – it will not be able to connect
to GitHub. To fix this, make sure your Dockerfile recipe contains:
apt-get install apt-transport-https ca-certificates -y
update-ca-certificates
See how we do this in ci/docker-images/ubuntu/noble.
Pushing an image to GitHub Container Registry
GitHub Container Registry (ghcr.io) is a space for hosting and managing
your docker images. In the next step, we will push our image to ghcr.io.
Note that what is pushed is not the Dockerfile, it’s the entire image.
First, we need to ensure you have the correct credentials. This only needs to be done once.
Log in to GitHub, and click on your portrait on the top right.
In the pull-down menu that opens, near the bottom, click on
Settings(cogwheel).In the pane on the left that opened, at the very very bottom click on
<> Developer settings.In the new pane on the left, click on
Personal access tokens, and thenTokens (classic).Find your PAT and click on it.
Under
Select scopesensure that you checked:write:packages,delete:packages, andworkflow.Click the green
Update tokenbutton at the bottom if you had to check any boxes. If not, your PAT was already good to go.
Second, and that will have to happen any time you push an image,
we need to log in to ghcr.io. To do this, issue:
echo <YOUR_PAT> | docker login ghcr.io -u <YOUR_USERNAME> --password-stdin
… where, naturally, you will replace <YOUR_PAT> by your Personal Access
Token, and <YOUR_USERNAME> with your GitHub username.
Subsequently, create a new tag. For example in my case that would be:
docker tag onetep:noble ghcr.io/jacekdziedzic/onetep:noble
This ties the name of the local image (here: onetep:noble) to the name
of the pushed image (here: ghcr.io/jacekdziedzic/onetep:noble). It is
absolutely crucial that whatever your username is, it needs to lowercasified
at this point. Even though my username is JacekDziedzic, I had to use
jacekdziedzic at this stage.
Finally, to push the image I would do:
docker push ghcr.io/jacekdziedzic/onetep:noble
… where the lowercase is again crucial.
As a side note, if you ever decide you need to get rid of an image pushed
to ghcr.io, you can issue something like:
docker rmi ghcr.io/name:tag
… where your lowercasified username would be part of the name.
We now have the image on ghcr.io. The only remaining issue is that it is
private to the user (here: me), and not accessible from our GitHub Action workflow!
To fix this, follow these steps.
Go to the repository GitHub page.
At the top right, click on
Settings(cogwheel).In the pane on the left, under
Security/Secrets and variablesgo toActionsIn the
Secretstab, clickNew repository secret.One of these secrets is your username, I added it under
JACEKS_USERNAME, the other is your PAT (the one with the correct credentials for managing packages). I added it unserJACEKS_PAT.In the YAML file that will access the Docker image you just pushed, have a section like this after the
runs-onsection:container: image: ghcr.io/jacekdziedzic/onetep:noble credentials: username: ${{ secrets.JACEKS_USERNAME }} password: ${{ secrets.JACEKS_PAT }}Here,
imageis the image tag you just pushed, and the names of the secrets correspond to the secrets you just added to the repository. The spaces after{{and before}}are significant.
More details on what we just did can be found at https://dev.to/willvelida/pushing-container-images-to-github-container-registry-with-github-actions-1m6b.
Trimmed boxes
- Author:
Jacek Dziedzic, University of Southampton
Trimmed boxes are an internal detail of how NGWFs (or other quantities) on the double grid can be stored, manipulated and communicated with high efficiency. They are used in fast density and in fast locpot integrals. Here we describe the rationale and implementation details.
Notation.
A denotes atoms local to a process. B denotes atoms that S-overlap with atoms A, they are, in general, not local. NGWFs on A are indexed with a, NGWFs on B are indexed with b, and so Aa and Bb can be used to index NGWFs globally. NGWFs Aa are local, NGWFs Bb are, in general, not. Depending on who you ask, Aa NGWFs are sometimes termed “col”, “ket” or “right”; Bb NGWFs are sometimes termed “row”, “bra” or “left”.
Rationale
ONETEP often works with quantities that have been interpolated to the double grid.
A prime example would be NGWFs being FFT-interpolated from the coarse grid to the
double grid in the calculation of the density. Another example would be rowsums,
that is, quantities of the form rowsum_Aa = sum_\Bb K^Aa,Bb \phi_Bb, which,
in the conventional (slow) calculation of the density are also interpolated
from the coarse grid to the double grid. A third example would be the local
potential that we obtain on the double grid.
FFT interpolation from the coarse grid to the double grid causes spilling. Quantities that were localised in a coarse-grid tightbox now delocalise into the entire double FFT-box. Spilling is illustrated schematically in Fig. 12, and an actual isoline for an s-like NGWF is shown in Fig. 13.

Fig. 12 “Spilling” of an NGWF due to Fourier interpolation. Left panel – NGWF (red) in an FFT-box (blue) on the coarse grid in the simulation cell (black). Right panel – NGWF (red) in a double FFT-box (blue) on the double grid in the simulation cell (black). The grid on the right is twice as fine (not shown). The orange dashed line shows the original shape of the NGWF.

Fig. 13 “Spilling” of an s-like NGWF due to Fourier interpolation from the coarse grid to the double grid.
Conventionally, ONETEP works with the entire spilled NGWFs, because the spilled part is necessary for accuracy. This is cumbersome. If a coarse FFT-box is, say, the size of 3 x 3 x 3 tightboxes, and the number of points is doubled in each direction by moving to the double grid, and the volume of a box circumsribing a sphere is about twice that of the sphere, this representation takes about 430 times more memory. We cannot, for instance, store more than a few of such boxes.
Fortunately, we can get sufficient accuracy even if we restrict ourselves to a subset
of the interpolated points in the double FFT-boxes. It turns out that only ~1-5% of the
points in the double FFT-box are needed to recover 99.9999-99.999999% of the charge of
the NGWF (which is one electron). This approach is, thus, an
approximation, but it is well-controllable. The points to be kept are selected
based on a threshold – we keep all points whose (absolute) value is below trimmed_boxes_threshold.
We call this process trimming. The machinery for trimming now resides in the
trimmed_boxes module. The concept of trimming can be applied to other quantities
in double FFT-boxes – for instance, we also trim rowsum_Aa, and, if fast_locpot_int T
is in effect, the local potential in the sphere of \phi_Aa.
The main question is how to store and manipulate interpolated NGWFs (or rowsums, etc.) accurately and efficiently, that is, how to store and manipulate the points encompassed by a chosen isoline (red) in Fig. 12, right panel. The region of interest does not have to be contiguous.
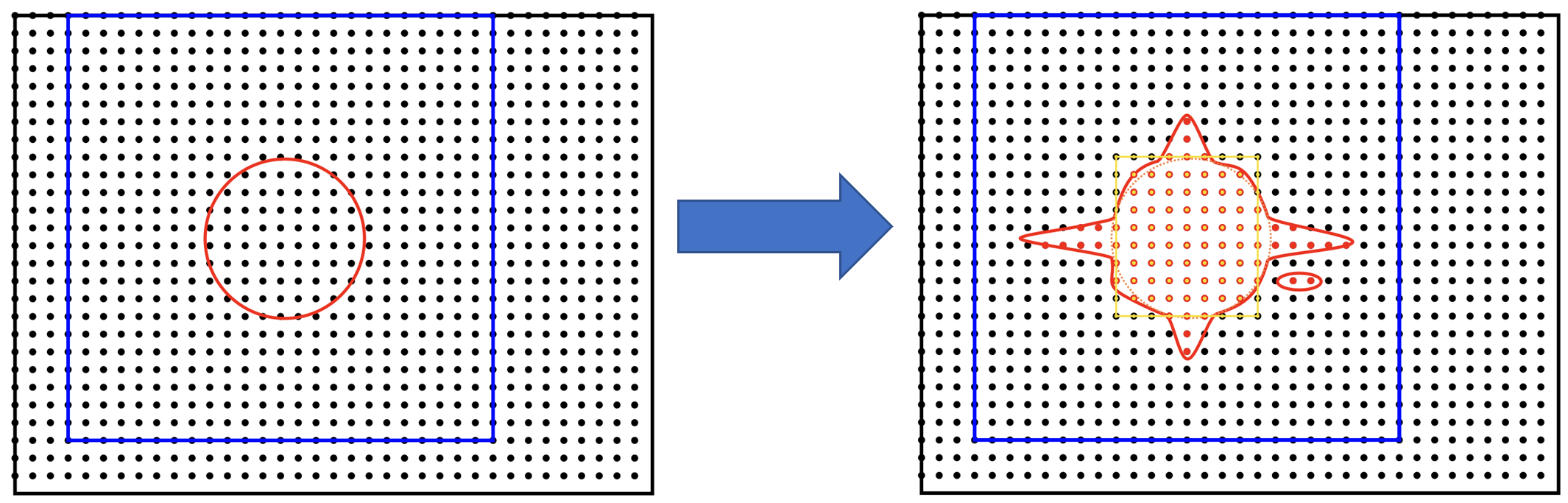
Fig. 14 Storing only the points in the double tight-box (shown in orange) is not sufficiently accurate. Some points that matter are contained in the Fourier ringing that is outside the tight-box.
The naive approach of storing just the points in the “double tight-box” of the NGWF (as shown Fig. 14) turns out to be almost sufficiently accurate, but not quite, to get convergence to default RMS thresholds. It’s also not controllable.
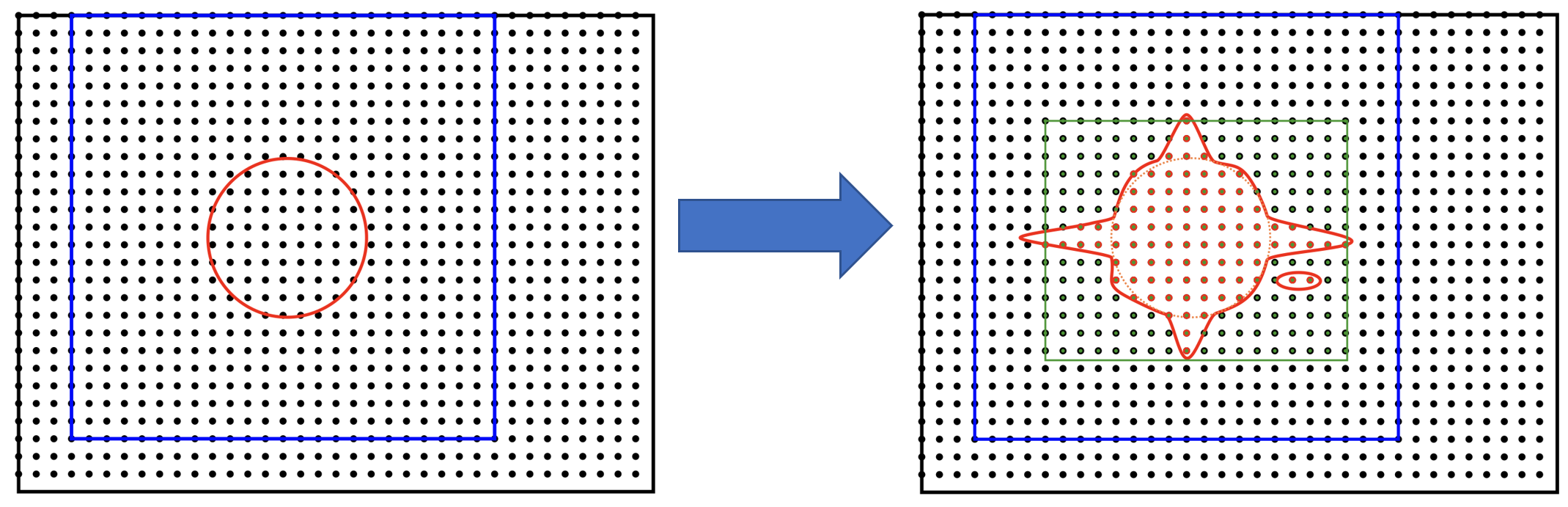
Fig. 15 Storing all the points in a box that covers an isoline is impractical, because the Fourier ringing extends far along the box axes (cf. Fig. 13), and we wind up storing points that are irrelevant (shown in green and not in red).
An alternative is to choose a threshold for the values of the NGWF (or rowsum, etc.) and to construct the smallest cuboid (or actually a parallelepiped) that encompasses all those points, as shown Fig. 15. This is controllable (via the threshold), but not very economical, because we store many more points than are necessary. This is because the ringing extends almost exclusively along the axes of the cell, practically to the faces of the double FFT-box. We’d like to keep this ringing, but not the points in the bulk of the double FFT-box.

Fig. 16 Storing “just the points we need”, in a naive fashion, by storing where (linear indices on the double grid), and what (values). This automatically takes care of the non-contiguity of the data we want to store.
Trimming
We can find which points we need (all points whose value is below a chosen threshold), and then remember their positions and values, like shown in Fig. 16. For positions it is convenient to use a linear index on the double grid – this makes them absolute (rather than relative to the double FFT-box), and permits handling PBCs at this stage.
Of course, such indexed approach is inefficient. Manipulating this representation is slow, and it takes more space than needed – we need to store an integer index in addition to every double precision value. However, we can exploit the fact that much of the region of interest is contiguous. This lets us proceed with a run-length encoding, as shown in Fig. 17 – we can store starting positions, run lengths (counts), and values.

Fig. 17 Storing “just the points we need”, using RLE compression, by storing where (linear indices on the double grid), how many (run lengths) and what (values). This automatically takes care of the non-contiguity of the data we want to store, but is efficient. Note that there are, in general, multiple values (red) for every run (shown in green).
For typical thresholds, the average run length is about 30. That means we only have to store two integers for every 30 double precision real values, so the overhead is minimal. Recall that we only keep 1-5% of the points in the double FFT-box, which means we can afford storing and communicating such compressed trimmed boxes. As will be shown later, manipulating them can also be done efficiently.
Summary: trimming.
Trimming consists in extracting an RLE-compressed representation of all points in a double FFT-box whose (absolute) values are below a specified threshold.
Bursts
We are often interested in calculating products of trimmed quantities.
For NGWFs in particular this has to be done in the inner loop, because even
if we can afford to store all trimmed NGWFs, we cannot afford to store entire products,
there’s just too many of these. However, we can store information on which parts of
the NGWFs overlap, which boils down to determining which runs in \phi_Aa overlap
where with which runs in \phi_Bb and by how much. These overlaps are the
bursts in which we will calculate sums and products later.
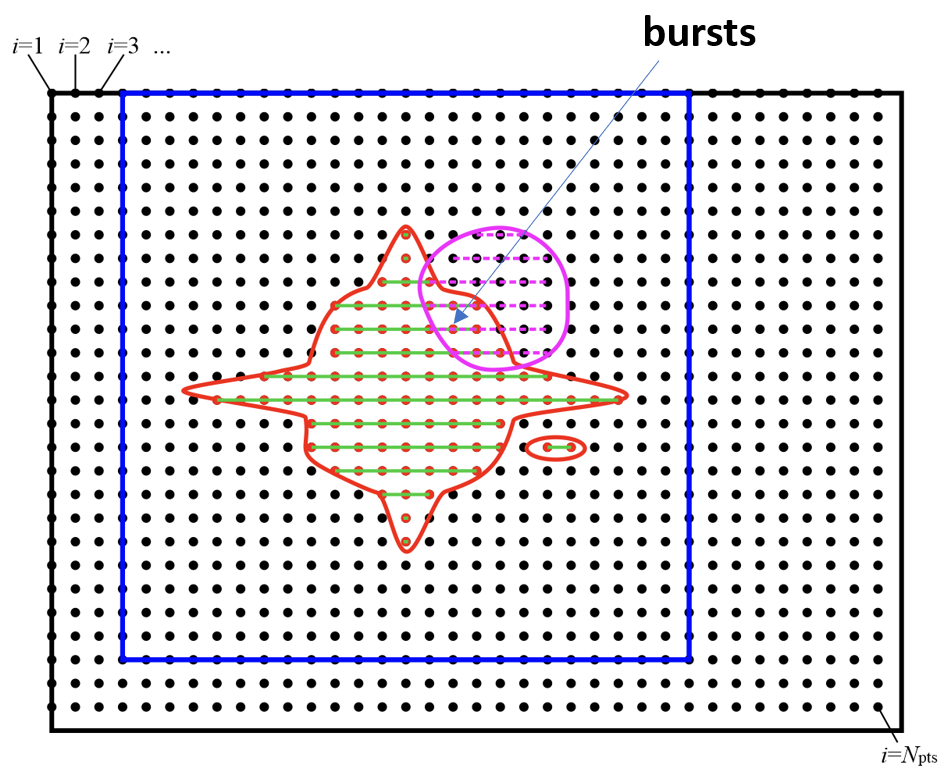
Fig. 18 To calculate the product between two compressed trimmed NGWFs, we first determine bursts, i.e. the overlaps between runs of NGWF Aa (green) and runs of NGWF Bb (magenta). Bursts are shown as green-magenta dashes.
The bursts can be determined outside of the inner loop and stored. Bursts do not store any information on the values, only
start and end indices to the values in \phi_Aa and \phi_Bb. Using this information we can calculate \sum_\Bb K^Aa,B \phi_Bb
more efficiently in the inner loop.
We can also use bursts to calculate products of \phi_Aa and rowsum_Aa, although, as we will see later,
this is not very efficient. It’s better to force rowsum_Aa to have the same shape as \phi_Aa using
moulding.
Summary: bursts.
Bursts are a mechanism for efficiently calculating products of overlapping trimmed boxes, typically NGWFs. They require substantial memory.
Moulding
When a trimmed quantity T is multiplied by another quantity Q, we only care about the points in the mask of T. All other points are zero. We can thus be smart, and carve out only a T–shaped part of Q for the product, and store it as a trimmed quantity. This process is called moulding. Following moulding, calculating a product is trivial – it’s just a pointwise operation on two trimmed quantities with the same masks.
We currently perform it in two scenarios:
in
fast_density_method 3we mouldrowsum_Aa, which is obtained from FFT interpolation, to the shape of\phi_Aa,in
fast_locpot_intwe mould the local potential from the double-grid cell to the shape of\phi_Aato obtain the part of the local potential that is relevant to\phi_Aa.
Summary: moulding.
Moulding is the process of extracting, from a double grid, a quantity in the shape of another quantity, typically an NGWF.
Keywords
See Fast density calculation (for users).
Fast density calculation (for developers)
- Author:
Jacek Dziedzic, University of Southampton
This section describes the “fast density” approach introduced in ONETEP 7.1.8 in January 2024. This is developer-oriented material – for a user manual, see Fast density calculation (for users). This documentation pertains to ONETEP 7.3.50 and later. If you are using a version of ONETEP older than 7.3.50, please update – not everything you read here will be applicable otherwise.
There are two slightly different methods for “fast density”, selected via
fast_density_method 1 and fast_density_method 2, with the latter now the default.
We focus on the calculation on the double grid. If fine_grid_scale is different from 2.0,
the density gets interpolated from the double to the fine grid, regardless of the approach
for calculating the density on the double grid.
Notation.
A denotes atoms local to a process. B denotes atoms that S-overlap with atoms A, they are, in general, not local. NGWFs on A are indexed with a, NGWFs on B are indexed with b, and so Aa and Bb can be used to index NGWFs globally. NGWFs Aa are local, NGWFs Bb are, in general, not. Depending on who you ask, Aa NGWFs are sometimes termed “col”, “ket” or “right”; Bb NGWFs are sometimes termed “row”, “bra” or “left”.
Rationale
The usual (“slow”) method for calculating electronic density in ONETEP proceeds as follows:
// slow density
for all local atoms A {
dens_A = 0
for all NGWFs a on A {
(1) Transfer \phi_Aa to FFT-box.
(2) Calculate rowsum_Aa = sum_\Bb K^Aa,Bb \phi_Bb in FFT-box.
(3) FFT-interpolate \phi_Aa and rowsum_Aa to a double FFT-box.
(4) Multiply dens_Aa = \phi_Aa * rowsum_Aa in double FFT-box.
(5) dens_A += dens_Aa.
}
(6) Deposit box containing dens_A to double grid.
}
All \phi_Aa are local, so are K^Aa,Bb. Stage (2) involves comms of \phi_Bb in PPDs via function_ops.
Stage (6) involves comms of atom-densities dens_A via cell_grid_deposit_box(). The algorithm proceeds in
batches (to conserve memory), and is OMP-parallelised. Comms must those be perofmed carefully, are done from $OMP MASTER regions in
function_ops_sum_fftbox_batch() and $OMP CRITICAL in density_batch_interp_deposit().
The number of FFTs done is \(2 N_{\textrm{NGWF}} N_{\textrm{outer}} N_{\textrm{inner}}\), where \(N_{\textrm{NGWF}}\) is the number of NGWFs in the system, \(N_{\textrm{outer}}\) is the number of outer (NGWF) loop iterations, \(N_{\textrm{inner}}\) is the number of inner (LNV, EDFT) iterations. We ignore line searches in this estimate for simplicity. In practice real FFTs are done in pairs throught a complex FFT, but we ignore this for simplicity.
- The main drawbacks of this approach are:
Having to repeat FFTs on
\phi_Aain the inner loop, even though they do not change.Having to repeat FFTs on
rowsum_Aain the inner loop, becauseK^Aa,Bbchanges.Interspersing comms with calculation in
function_ops_sum_fftbox_batch(), which makes GPU-porting difficult, and comms tricky.Having to calculate products of
\phi_Aaand\phi_Bbin double FFT-boxes, even though “what matters” is almost exclusively contained in the double tight-box of\phi_Aa. We need to do the whole double FFT-boxes because of Fourier ringing from the interpolation.Multiple depositions (and comms) to the same points in (6), because boxes of nearby A overlap.
(1) cannot be addressed directly by storing the interpolated \phi_Aa for the duration of the inner loop, because we
cannot afford to store full double FFT-boxes. However, we can leverage Trimmed boxes. By using only a fraction of the points in the double FFT-boxes, we are able to store the interpolated NGWFs. This lets
us address (1) directly – we only interpolate \phi_Aa at the beginning of the inner loop, and can now afford to
store the interpolated versions.
We address (2) and (3) by first interpolating only \phi_Aa, and then
communicating them to where they are needed (and where they become \phi_Bb).
We use remote_mod for that, which separates the comms from the FFTs.
In fast_density_method 1 we communicate \phi_Bb in the form of trimmed boxes.
In fast_density_method 2 we communicate \phi_Bb in PPDs on the coarse grid,
and process them at destination. Of course, when communicating trimmed boxes, we only communicate the relevant points,
not the entire double FFT-boxes.
Methods
In fast_density_method 1 we no longer have to interpolate rowsum_Aa = sum_\Bb K^Aa,Bb \phi_Bb,
and we avoid doing FFTs in the inner loop entirely – we build the rowsums from
the trimmed \phi_Bb using bursts (described earlier). The number of FFTs is then \(N_{\textrm{NGWF}} N_{\textrm{outer}}\) (we interpolate all NGWFs
every time they change), which saves 1-2 orders of magnitude in the number of FFTs. There is a price to pay, though:
we need memory to store the trimmed NGWFs, we have to communicate trimmed NGWFs rather than coarse-grid PPDs,
and we need to do rowsum_Aa = \sum_\Bb K^Aa,B \phi_Bb on the new representation somehow. If the latter can be done efficiently,
we are addressing (4) above, too.
In fast_density_method 2 we similarly do the FFTs in the inner loop, but only for the rowsums,
as trimmed \phi_Aa are stored for the entire duration of the inner loop.
However, we are smart and realize that we do not need the entire rowsum_Aa,
but only its part that overlaps with \phi_Aa – as these are multiplied
by one another later on. Thus, rather than trim rowsum_Aa to a threshold,
we only keep a \phi_Aa-shaped fragment. This process is called moulding (described earlier)
– we take data from a double FFT-box and mould it to a shape of a previously
trimmed NGWF. In so doing, we avoid bursts altogether – multiplying two
trimmed quantities with the same shape (“mask”) is a simple pointwise job.
This method has a vastly smaller memory footprint, and is light on comms, because it only
transmits NGWFs in PPDs on the coarse grid.
Finally, this method GPU-ports well.
The fast density approach thus proceeds in two stages – one that is performed every time NGWFs change, and one that is performed
in the inner loop. The details of the stages depend on fast_density_method.
The following table summarizes the main differences between the three methods.
Detail |
method 1 |
method 2 |
|---|---|---|
FFTs done for |
in outer loop only |
|
FFT load |
minimal |
~half of original can be done on GPU |
Communicated NGWFs |
all required |
|
Communicated how |
as trimmed boxes |
in PPDs on coarse |
Comms load |
significant |
minimal |
Trimmed storage |
|
|
Bursts |
yes, many (pairs Aa-Bb) |
no |
Memory load |
high |
low |
Expected CPU performance |
very good |
good |
Expected GPU performance |
very good |
excellent |
On a CPU, typical speed-ups obtained using fast density range from 2x to 6x for the total time spent calculating the density, and between 10% and 50% can be shaved off the total calculation walltime.
On a GPU, typical speed-ups would be between 10x and 16x for the total time spent calculating the density, and between 50% and 70% shaved off the total calculation walltime. This measured is in a fair comparison – a CPU-only compute node vs. the same compute node with a reasonable GPU (e.g. an NVIDIA A100).
Cost
- The main drawback of fast density is increased memory consumption. There are two main components:
The trimmed NGWF data itself, which is, to a large extent, replicated. In
fast_density_method 1a single trimmed NGWF can be needed on many processes, because it could be a\phi_Bbto many NGWFs Aa. The same holds for NGWFs in PPDs forfast_density_method 2. Moreover, this memory requirement does not scale inverse-linearly with the number of processes. That is, increasing the node count by a factor of two doesn’t reduce the memory requirement by a factor of two, because there is more replication.The burst data (in
fast_density_method 1).
Both (A) and (B) depend on the trimming threshold, and the shape of the NGWFs. Both tend to increase during the NGWF optimisation as the NGWFs delocalise somewhat.
A typical plot of the memory used by fast_density_method 1 is shown in Fig. 19.
For this calculation the slow approach took 1893s (33.3% of the total walltime), and the fast approach
took 727s (14.8% of total walltime), for a speed-up of 2.6x. One-eighth of the total walltime was
shaved off. Of the 727s only 66s were spent doing FFTs.

Fig. 19 Memory used by the slow approach (magenta) and the fast approach (method 1) (cyan) for a calculation on ethylene carbonate (4000 atoms) on 32 nodes of Archer2. 9 a0 NGWFs, 829 eV, EDFT. 117x117x117 FFT-box, 140x140x140 cell. 16 OMP threads were used.
Accuracy
The accuracy of the fast density approach can be demonstrated on an example – we consider the binding energy of mannitol to 300 water molecules. The system is shown in Fig. 20.

Fig. 20 Our testcase: mannitol bound to 300 water molecules (926 atoms). 811 eV KE cutoff, 9 a0 NGWFs, 8 LNV iterations.
Performance
I ran this testcase on 16 nodes of HSUper (8 processes on a node, with 9 threads each, saturating all
72 CPU cores on a node) – both the complex and the water shell. The mannitol itself was ran on 1 node,
because it’s small. I used the default settings, only specifying fast_density T. Thus,
this is for a calculation with fast_density_method 1.
Quantity |
Slow density |
Fast density |
|---|---|---|
Binding energy (kcal/mol) |
-79.9027 |
-79.9014 |
Total walltime |
1016s |
718s (-29%) |
Time to calculate density |
520s |
239s |
Time spent doing FFTs |
160s |
23s |
High-mem watermark on a node |
55.6 GiB |
69.7 GiB |
As seen from the above table, we are accurate to ~0.001 kcal/mol, while shaving off 29% from the total walltime. The density calculation itself was faster by a factor of 2.2.
I also performed scaling tests, using a 701-atom protein scoop at 827 eV, 9a0 NGWFs, 8 LNV iterations. I only ran it for 4 NGWF iterations because it’s not properly terminated, which leads to a zero band-gap, meaning it cannot be reliably converged to default thresholds (with either density method). These were run on different numbers of nodes of HSUper, with 8 processes and 9 OMP threads per node.
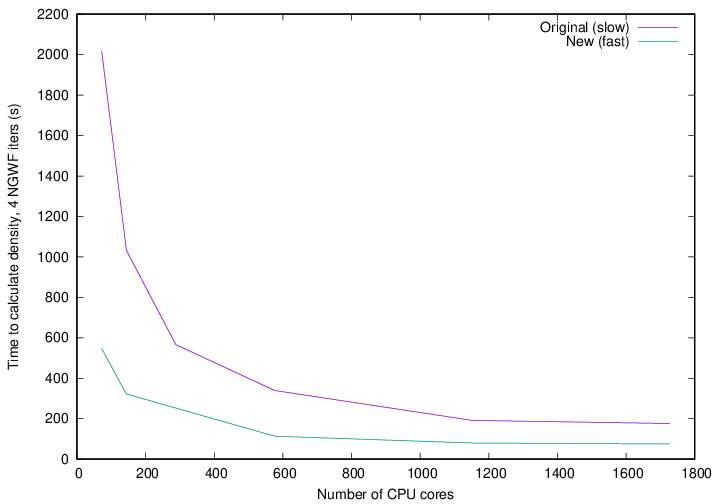
Fig. 21 Time to calculate density in 4 NGWF iterations of a 701-atom protein scoop.
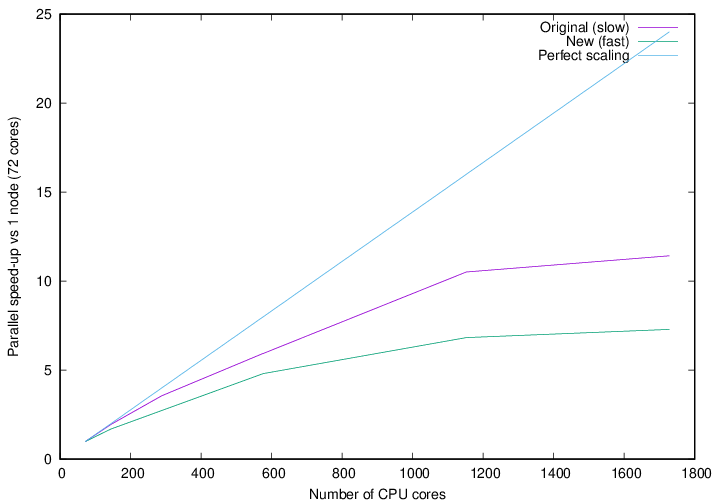
Fig. 22 Strong parallel scaling of the two methods of calculating the density in for a 701-atom protein scoop.
Fig. 21 shows the walltime of the density calculation for the slow and fast approaches, while Fig. 22 shows the strong scaling with respect to one node. It is clear that the fast approach is quite a bit faster than the original approach, although it does not scale that well to high core counts. Keep in mind that we pushed this system quite far by running 701 atoms on over 1600 CPU cores.
More detailed benchmarks of fast_density_method 2 will follow at some point.
Keywords
Directions for improvement
- This approach could be improved in a number of ways:
Setting up an allowance for used RAM, similarly to what is done in HFx. This would enable graceful performance degradation in low-memory scenarios. This could be achieved by not storing all the bursts, only those that fit within the allowance. The remaining bursts would have to be recalculated on the fly in the inner loop.
Making it compatible with EMFT, complex NGWFs and mixed bases.
Adding an
$OMP SCHEDULEtoggle betweenSTATICandDYNAMICindensity_on_dbl_grid_fast()for more control over determinism vs efficiency. Currently we useSCHEDULE(STATIC)to get more deterministic results, butSCHEDULE(DYNAMIC)offers better efficiency. Toggling this at runtime is not trivial (omp_set_schedule()).Dynamically selecting
MAX_TNGWF_SIZE. It’s currently a constant, andpersistent_packed_tngwfis not an allocatable.A smarter way to flatten the computed density. Currently each process has their own density that spans the entire cell and only contains contributions from the Aa NGWF it owns. We flatten it by a series of reduce operations over all nodes. This is the main killer of parallel performance.
Fast local potential integrals (for developers)
- Author:
Jacek Dziedzic, University of Southampton
This section describes the “fast locpot int” approach introduced in ONETEP 7.1.50 in July 2024. This is developer-oriented material – for a user manual, see Fast local potential integrals (for users). This documentation pertains to ONETEP 7.3.50 and later. If you are using a version of ONETEP older than 7.3.50, please update – not everything you read here will be applicable otherwise.
We focus on the calculation on the double grid. If fine_grid_scale is different from 2.0,
the local potential first gets filtered from the fine to the double grid, regardless of the approach
for calculating the local potential integrals the double grid.
Notation.
A denotes atoms local to a process. B denotes atoms that S-overlap with atoms A, they are, in general, not local. NGWFs on A are indexed with a, NGWFs on B are indexed with b, and so Aa and Bb can be used to index NGWFs globally. NGWFs Aa are local, NGWFs Bb are, in general, not. Depending on who you ask, Aa NGWFs are sometimes termed “col”, “ket” or “right”; Bb NGWFs are sometimes termed “row”, “bra” or “left”.
Rationale
The usual (“slow”) method for calculating local potential integrals in ONETEP
is not very efficient. It intersperses computations with comms (cell_grid_extract_box()
is called from potential_apply_to_ngwf_batch(), plan comms in function_ops_brappd_ketfftbox()).
It multiplies the local potential with \phi_Bb in double FFT-boxes
in potential_apply_to_ngwf_batch().
Our goal is to improve on that, leveraging
remote_mod for comms, and using Trimmed boxes for operating on double-grid
quantities. The implementation, in integrals_fast_mod is remarkably lean,
and takes place almost exclusively in integrals_fast_locpot_dbl_grid().
Methods
We proceed as follows:
trimmed_boxes_new_ngwfs()makes sure that all local NGWFs Aa have been trimmed. It also communicates all requisite NGWFs Bb in coarse-grid PPDs. Iffast_densityis in effect, this has been done before, and is effectively free.integrals_fast_new_ngwfs()establishes the union of all points spanned by local NGWFs Aa (viatrimmed_boxes_all_local_positions_in_cell()). These are the points of interest, e.g. we will need the local potential only for these points. By establishing the union, we avoid communicating the same points many times, as part of multiple different NGWFs. Subsequently, iffast_ngwfs T, the communicated NGWFs Bb are converted to the rod representation. If GPUs are in use, NGWFs Bb are copied to the device.We communicate the local potential, only for the points of interest, to whichever ranks need them. This happens in
integrals_fast_extract_locpot().Using
trimmed_boxes_mould_set_from_cell(), the previously trimmed local NGWFs Aa are used to mould corresponding trimmed locpots from the cell, for each local NGWF Aa. This happens in an OMP loop over Aa. At this point we havetngwfs– a trimmed representation of\phi_Aa, andtlocpots– a trimmed representation of\locpot_Aa, both with the same shape (mask).- In an OMP loop over
\phi_Aa, we Put the product
\phi_Aa*locpot_Aain double FFT-box.Fourier filter to a coarse FFT-box.
Dot with all S-overlapping
\phi_Bb, store in a SPAM3 matrix. Withfast_ngwfs F, this is done by dotting PPDs with an FFT-box inintegrals_fast_bra_ketfftbox(). Withfast_ngwfs T, we dot rods with an FFT-box inrod_rep_dot_with_box(), using GPUs if available.
Notably,
\phi_Bbhave been made available byremote_mod, so no comms are needed. We can simply usebasis_dot_function_with_box_fast()when working with PPDs androd_rep_dot_with_box()when working with rods.- In an OMP loop over
Symmetrise the SPAM3 matrix.
When using CPUs only, much of the time is spent in the Fourier filtering.
With a GPU, this becomes much faster. Copyin is avoided at all times. Copyout
is avoided when fast_locpot_int_fast_ngwfs T is in use.
Performance
Two testcases were benchmarked so far – a ~2600-atom lysozyme protein with LNV, and a 353-atom Pt cluster with EDFT. Only the time for the calculation of the local potential integrals was measured. Measurements were done on a 48-core node with and without an A100 GPU.
For the LNV testcase I obtained a speed-up of 5.3x on a CPU, and a further 2.7x speed-up once the GPU was used, for a total speed-up of 14.3x. For the EDFT testcase I obtained a speed-up of 3.6x on a CPU, and a further 3.2x speed-up once the GPU was used, for a total speed-up of 11.5x.
Fast NGWFs (for developers)
- Author:
Jacek Dziedzic, University of Southampton
This section describes the “fast ngwfs” approach introduced in ONETEP 7.3.26 in December 2024. This is developer-oriented material – for a user manual, see Fast NGWFs (for users). This documentation pertains to ONETEP 7.3.50 and later. If you are using a version of ONETEP older than 7.3.50, please update – not everything you read here will be applicable otherwise.
Rationale
The usual (“slow”) method for working with NGWFs on the coarse grid uses PPDs – parallelepipeds with axes parallel to those of the simulation cell, spanning an integer number of grid points. In practice we use flat PPDs, as the default number of points along a3 is 1, unless HFx is in use (where it’s more beneficial to use larger PPDs). Any NGWF sphere can be covered fully with a number of PPDs. The coarse grid data is then stored as points in PPDs. Operations on PPDs are straightforward and fast – there is data contiguity because the data in a PPD is stored as a linear 1D array.
Operations that mix PPDs and FFT-boxes are less straightforward and not as fast
– there is data contiguity for the entire length of the PPD along a1, but
not a2 or a3. Furthermore, every time a PPD intersects with an FFT-box,
we need to establish which parts of the PPD overlap
with the FFT-box, and which ones stick out and need to be ignored. This is
further complicated by ppd_loc – a feature for remembering of a PPD
is actually a periodic image and needs to be unwrapped back from the box to the
image. Such PPDs are sometimes termed improper. The limited contiguity (a PPD
is typically only 5-7 points long) and no GPU support are further drawbacks.
With fast_density_fast_ngwfs T we switch to a rod representation for NGWFs
in the calculation of fast density.
With fast_locpot_int_fast_ngwfs T we switch to a rod representation for NGWFs
in the calculation of fast local potential integrals.
A rod is oriented along the a1 direction and spans an integer number of PPDs. Its width along a2 and a3 is one point.
Operations mixing rods and FFT-boxes are much faster, because they leverage contiguity – a rod is typically ~40-points long. There are also fewer operations to determine which parts of a rod stick out of the FFT-box and which parts overlap. Finally, rod operations have been GPU ported.
Details
For more details, see the banner in rod_rep_mod.F90, where rods, bunches, slots,
and handling of periodicity are described.
State of the art
Currently (February 2025, v7.3.50), fast NGWFs can be used in fast local potential
integrals (fast_locpot_int T), and in the fast
density calculation (fast_density T).
The rest of ONETEP certainly does not benefit from fast NGWFs, yet.
Performance
No detailed performance analysis is available, but here are some tentative numbers.
- Dotting two 9a0 NGWFs takes about:
13 us when using PPDs for the bra and an FFT-box for the ket,
4.2 us when using PPDs for both,
2.0 us when using rods for the bra and an FFT-box for the ket,
0.6 us on a GPU when using rods for the bra and an FFT-box for the ket.
In practice you will likely see very limited gains from fast NGWFs on a CPU, it’s mostly meant to speed up GPU calculations.
History
The earliest versions of the code, dating back to before 2005, were committed to a revision control system based on CVS. These files are still available on the TCM filesystem at /u/fs1/onestep/CVS_REPOSITORY. In around 2009 we moved to Subversion, using a repository still hosted on the TCM filesystem in Cambridge. The SVN history was migrated to Bitbucket, and subsequently to GitHub (2023) and can still be browsed within the current Git repository (though attribution to authors is often not correctly recorded).
In June 2018, the ONETEP project was migrated from a Subversion repository to a Git repository. The hosting of source code was simultaneously moved from cvs.tcm.phy.cam.ac.uk to Bitbucket.
In July 2023, the ONETEP project was migrated from Bitbucket to GitHub.